Practical Python based tools for linearity assessment.
Linearity assessment is a mandatory requirement in various statistical analysis. This post demonstrates Python-based statistical approaches to diagnose linearity and avoid pitfalls.
When validating analytical methods or modeling dose-response relationships, linearity is a cornerstone assumption but it’s often misunderstood. Many confuse \(R^2\) with linearity or overlook systematic deviations in response function: Signal=\(f\)(Concentration) or in accuracy response: Measured concentration = \(f\)(True concentration).
What we’ll cover:
What linearity really means: The conditional mean \(E[Y\mid X]\) as a straight line (\(\beta_0 + \beta_1 X\)), and why \(R^2\) isn’t enough.
How to detect nonlinearity: Visual tools (residual plots, LOWESS) and statistical tests (ANOVA lack-of-fit).
Pitfalls and solutions: From leverage points to systematic bias, and when to consider alternatives like polynomial or weighted regression.
Why it matters: Poor linearity assessment can lead to biased dose estimates.
When modeling a response \(Y\) as a function of \(X\), total variability can be partitioned into what the model explains and what remains as residual variability. With replicated measurements1 at fixed \(x\)\((n\ge 2\) per level\()\), this residual variability further splits into pure error2 (within‑level random scatter) and lack of fit3 (systematic deviation of the model’s mean function from the level means).
Linearity
From a modeling perspective, a linear model suggest a linear conditional mean over the design range, \(E[Y\mid X] = \beta_0 + \beta_1 X\). Model inadequacy appears as lack of fit, a systematic patterns the linear mean cannot capture (e.g., curvature, slope changes).
Important
Linearity :
Mathematical Form: \(Y = \beta_0 + \beta_1 X + \epsilon\)
Key Property: Constant slope (\(\beta_1\)) across all \(x\) values.
Lack of fit is diagnosed visually (scatter, regression line, LOWESS4, residuals vs fitted plot) and tested by comparing the linear model with richer alternatives such as a saturated model (one mean per level) when replicates are available, or augmented parametric forms (quadratic/cubic).
Note
A saturated model treats each observed \(x\) value as a separate category and estimates a mean for every level, so it captures all between‑level differences and leaves only within‑level (pure) error. In lack‑of‑fit testing we compare the saturated model’s residuals (pure error) to the linear model’s lack‑of‑fit to detect systematic departures such as curvature.
Diagnosis of non-linearity
Demonstration with a generated dataset with intentional curvature
In regression, analysis of variance (ANOVA) compares how much residual variability remains under competing models to decide whether a richer specification explains significantly more variation. For lack‑of‑fit diagnosis, we compare the linear model (y ~ x) against a saturated model (y ~ C(x)) that estimates one mean per concentration level.
Consider a generated dataset with intentional curvature at midlevel.
Generate data to demonstrate lack of fit
import numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport seaborn as snsimport statsmodels.api as smfrom statsmodels.formula.api import olsfrom scipy import statsfrom statsmodels.nonparametric.smoothers_lowess import lowess# Reproducibilityrs = np.random.default_rng(42)# 1) Design: 3 levels, 5 replicates eachlevels = np.array([0.0, 1.0, 2.0])replicates =5x = np.repeat(levels, replicates)# 2) Introduce lack-of-fit for demonstration purpose (curvature peaks at x=1)c =0.15noise_sd =0.06true_mean =1+2*x + c * x * (2- x)y = true_mean + rs.normal(0.0, noise_sd, size=x.size)df = pd.DataFrame({"x": x, "y": y})
Fitting the linear model
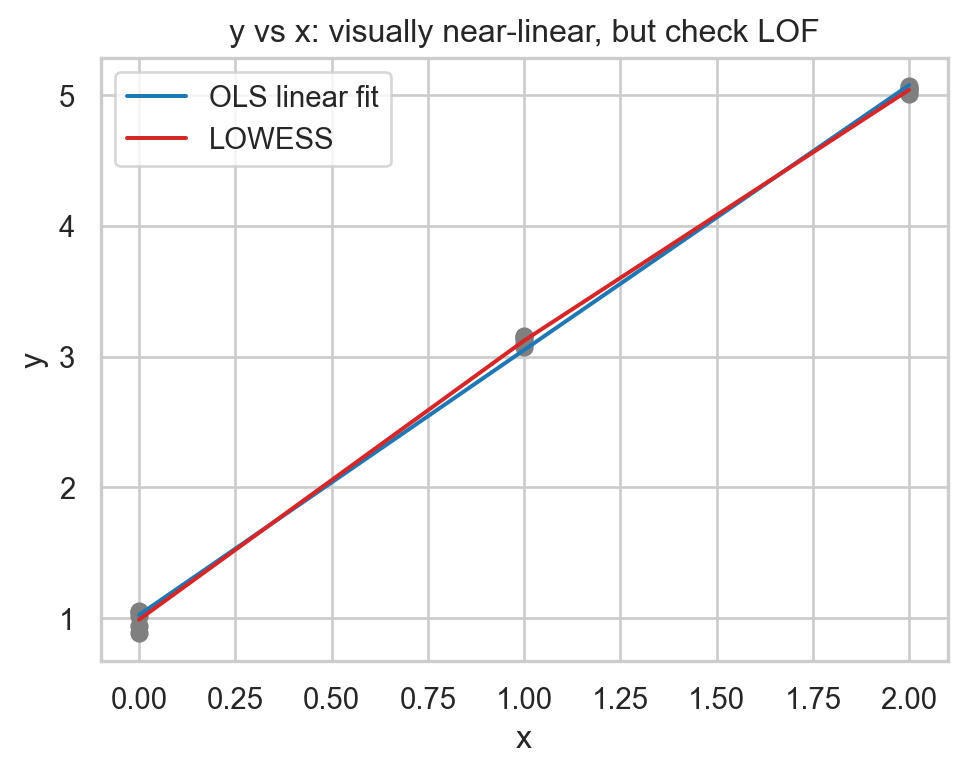
We fit a linear model and visualize departures from linearity using LOWESS (locally weighted regression) over the scatterplot (Figure 1). Altough the scatter appears roughly linear, the LOWESS curve may reveals systematic deviation (or not).
Fit linear model and plot Y vs X
# 3) Fit linear model (y ~ x) and visualize against LOWESSmod_lin = ols("y ~ x", data=df).fit()sns.set_theme(style="whitegrid")# y vs x (scatter + OLS + LOWESS)xx = np.linspace(df["x"].min(), df["x"].max(), 200)yy_lin = mod_lin.params["Intercept"] + mod_lin.params["x"] * xxlo_y = lowess(df["y"], df["x"], frac=0.7, it=0, return_sorted=True)plt.figure(figsize=(5.2, 4.2))sns.scatterplot(x="x", y="y", data=df, s=40, color="tab:gray", edgecolor=None)plt.plot(xx, yy_lin, color="tab:blue", label="OLS linear fit")plt.plot(lo_y[:,0], lo_y[:,1], color="tab:red", label="LOWESS")plt.title("y vs x: visually near-linear, but check LOF")plt.xlabel("x"); plt.ylabel("y"); plt.legend(); plt.tight_layout()plt.show()
Figure 1: Regression line and LOWESS
Model summary and interpretation
Statistics associated with this linear regression can be viewed using summary().
Show OLS summary table
mod_lin.summary()
OLS Regression Results
Dep. Variable:
y
R-squared:
0.998
Model:
OLS
Adj. R-squared:
0.998
Method:
Least Squares
F-statistic:
7770.
Date:
Thu, 30 Oct 2025
Prob (F-statistic):
1.93e-19
Time:
15:28:14
Log-Likelihood:
19.115
No. Observations:
15
AIC:
-34.23
Df Residuals:
13
BIC:
-32.81
Df Model:
1
Covariance Type:
nonrobust
coef
std err
t
P>|t|
[0.025
0.975]
Intercept
1.0240
0.030
34.511
0.000
0.960
1.088
x
2.0259
0.023
88.148
0.000
1.976
2.076
Omnibus:
0.204
Durbin-Watson:
1.434
Prob(Omnibus):
0.903
Jarque-Bera (JB):
0.320
Skew:
-0.222
Prob(JB):
0.852
Kurtosis:
2.438
Cond. No.
2.92
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Note
The “P>|t|” column tests whether each coefficient differs significantly from zero. However, significant coefficients don’t guarantee linearity.
Lack-of-fit test using ANOVA
In a linear model, the average response at each level \(x\) (i.e., \(E[Y \mid X = x]\)) is assumed to lie on the straight line \(\beta_0 + \beta_1 x\). Deviations from this line is detected via lack-of-fit tests or residual plots. To formally test linearity, we fit a saturated model treating \(x\) as categorical and compare it to the linear model. This model estimates a separate mean for each level of \(x\), effectively capturing all between-level differences (including potential nonlinearity). The comparison between the linear and saturated models isolates lack-of-fit variability, while the saturated model’s residuals reflect only pure error (within-level random variation).
Fit saturated model
mod_full = ols("y ~ C(x)", data=df).fit()
ANOVA comparison quantifies the lack-of-fit:
ANOVA comparison (linear vs saturated)
from statsmodels.stats.anova import anova_lmanova_table = anova_lm(mod_lin, mod_full)print(anova_table)
df_resid ssr df_diff ss_diff F Pr(>F)
0 13.0 0.068667 0.0 NaN NaN NaN
1 12.0 0.029975 1.0 0.038692 15.489637 0.001978
Result: The ANOVA (F(1, 12) = 15.49, p = 0.002) indicates significant lack of fit, meaning the linear model’s mean function is inadequate.
Why R² isn’t sufficient for linearity assessment
R² measures variance explained, not functional form
\(R^2\) reports the proportion of variance in \(Y\) explained by the model relative to an intercept-only baseline. While useful for goodness-of-fit, it doesn’t verify linearity. A curved relationship can yield high \(R^2\) with a straight line, and \(R^2\) increases with predictor range regardless of functional correctness.
\(R^2=0\): The model explains no more variance than the intercept-only horizontal line.
\(R^2=1\): The model explains all variance in \(Y\) (perfect fit).
Another demonstration with systematic bias
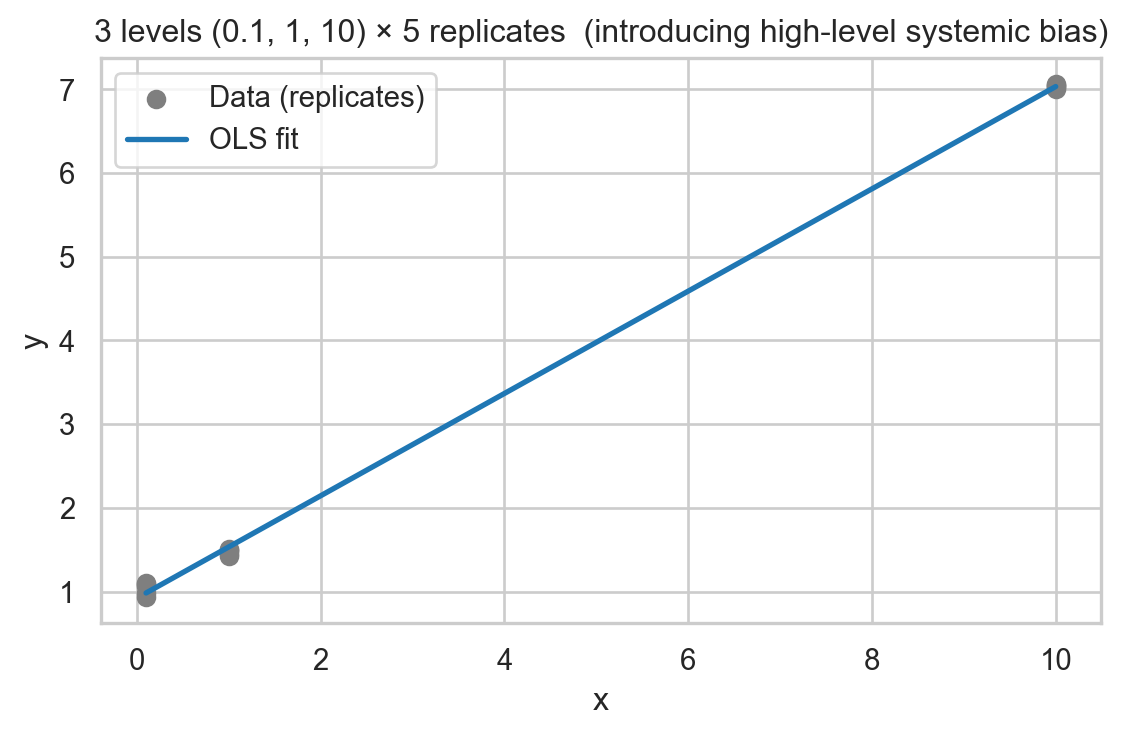
We generate normally distributed linear data (3 levels: 0.1, 1, 10; 5 replicates each) and introduce a systematic bias at \(x = 10\) (let’s imagine that for this high level the instrument, e.g., a pipette, has been changed for practical reasons and consistently overestimates by 10% compared to the first one used).
Generate a biased dataset for R²
# Minimal: 3 levels (0.1, 1, 10) × 5 replicates, plus a systematic bias at the highest levelimport numpy as npimport pandas as pdimport matplotlib.pyplot as pltimport statsmodels.api as sm# Reproducibilityrng = np.random.default_rng(42)# Design: 3 levels, 5 replicates eachlevels = np.array([0.1, 1.0, 10.0])replicates =5x = np.repeat(levels, replicates)# True linear relation and noisebeta0, beta1 =1.0, 0.5noise_sd =0.06y = beta0 + beta1 * x + rng.normal(0, noise_sd, size=x.size)# Lever effect: systematic bias +0.1 at the highest level (x == 10)y[x ==10.0] +=1.0# DataFrame for convenience - use distinct name to avoid overwriting previous dfdf_r2 = pd.DataFrame({"x": x, "y": y})# OLS fit (y ~ x) - using formula API for compatibility with influence_plotfrom statsmodels.formula.api import olsmodel_r2 = ols("y ~ x", data=df_r2).fit()# Predictions for plottingxx = np.linspace(df_r2["x"].min(), df_r2["x"].max(), 200)yy = model_r2.params["Intercept"] + model_r2.params["x"] * xx#print(f"intercept = {model_r2.params[0]:.3f}, slope = {model_r2.params[1]:.3f}, R^2 = {model_r2.rsquared:.3f}")# Plot (log x scale to reflect design)plt.figure(figsize=(6, 4))plt.scatter(df_r2["x"], df_r2["y"], s=40, color="tab:gray", label="Data (replicates)")plt.plot(xx, yy, color="tab:blue", lw=2, label="OLS fit")plt.xlabel("x")plt.ylabel("y")plt.title("3 levels (0.1, 1, 10) × 5 replicates (introducing high-level systemic bias)")plt.legend()plt.tight_layout()plt.show()
Scatter and OLS fit (bias at highest level)
Despite the systematic bias, R² remains high:
Show OLS summary
model_r2.summary()
OLS Regression Results
Dep. Variable:
y
R-squared:
0.999
Model:
OLS
Adj. R-squared:
0.999
Method:
Least Squares
F-statistic:
2.269e+04
Date:
Thu, 30 Oct 2025
Prob (F-statistic):
1.83e-22
Time:
15:28:14
Log-Likelihood:
19.624
No. Observations:
15
AIC:
-35.25
Df Residuals:
13
BIC:
-33.83
Df Model:
1
Covariance Type:
nonrobust
coef
std err
t
P>|t|
[0.025
0.975]
Intercept
0.9214
0.024
39.132
0.000
0.871
0.972
x
0.6113
0.004
150.637
0.000
0.603
0.620
Omnibus:
0.668
Durbin-Watson:
1.261
Prob(Omnibus):
0.716
Jarque-Bera (JB):
0.614
Skew:
0.406
Prob(JB):
0.735
Kurtosis:
2.431
Cond. No.
7.63
Notes: [1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
Diagnostic statistics interpretation
Beyond R², model.summary() provides diagnostic tests for residual normality and while this post focuses on linearity, regression diagnostics also include checks for:
Homoscedasticity (equal variance of residuals).
Normality of residuals.
Independence of observations.
Tip
If residual plots show a funnel shape (variance increases with \(x\)), your data may suffer from heteroscedasticity. This topic deserves its own post on how to detect and address unequal variance in regression models so stay tuned!
df_resid ssr df_diff ss_diff F Pr(>F)
0 13.0 0.064158 0.0 NaN NaN NaN
1 12.0 0.029975 1.0 0.034183 13.684441 0.00304
ANOVA detects significant lack of fit (p < 0.05), confirming that linear predictions systematically deviate from observed level means.
Residual diagnostics show the bias pattern
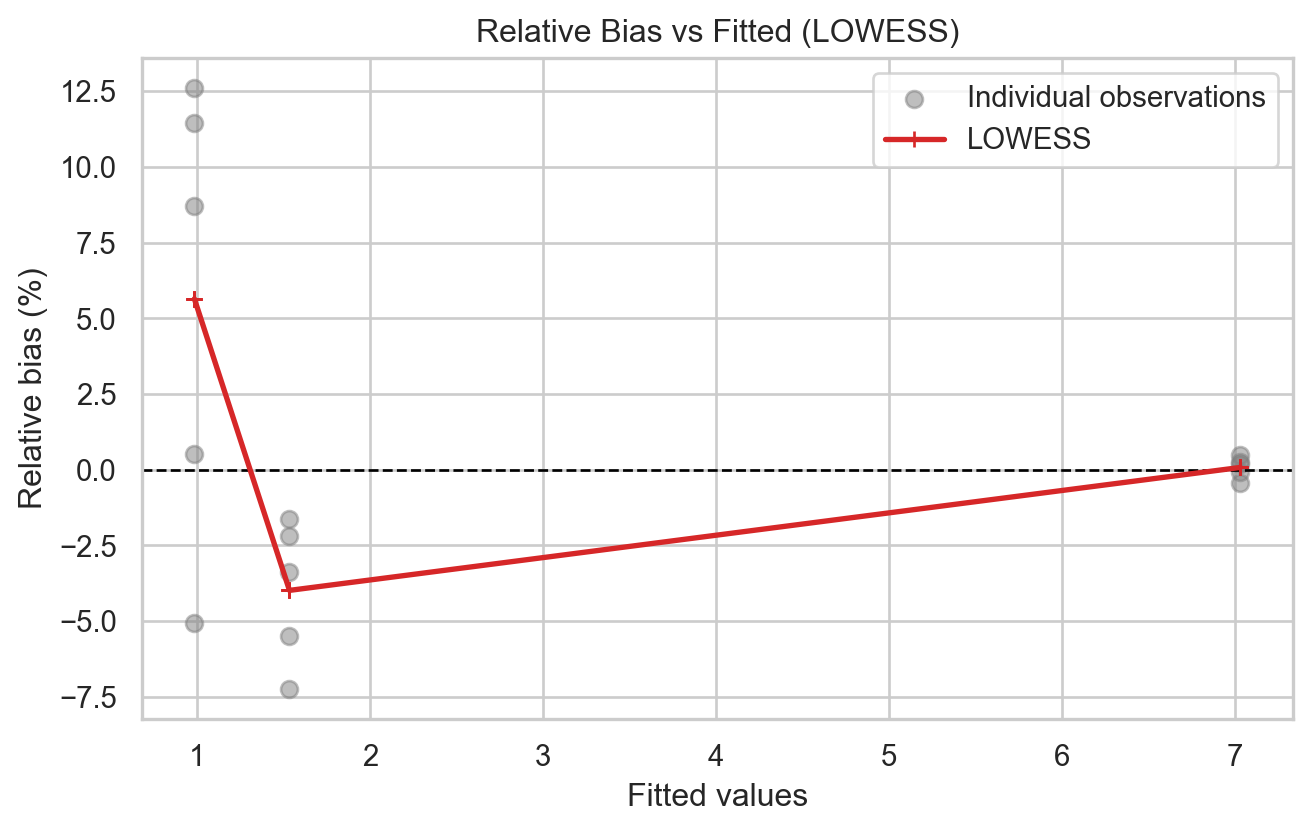
Plotting residuals (\((y - \hat{y}) / \hat{y}\)) vs fitted values (\(\hat{y}\)) reveals the systematic bias (Figure 2). Note that we plot relative bias (residuals as % of fitted values) to better visualize proportional deviations across the concentration range, and that for a simple regression with one predictor (\(X\)), we could equivalently plot residuals vs levels (\(X\)).
Plot: Relative bias vs fitted with LOWESS
from statsmodels.nonparametric.smoothers_lowess import lowessfitted_r2 = model_r2.fittedvaluesresid_r2 = model_r2.resid# Calculate relative bias (residuals as % of fitted values)relative_bias = (resid_r2 / fitted_r2) *100# Calculate mean relative bias at each level# level_stats = df_r2.assign(# fitted=fitted_r2,# rel_bias=relative_bias# ).groupby('x').agg(# mean_fitted=('fitted', 'mean'),# mean_rel_bias=('rel_bias', 'mean'),# se_rel_bias=('rel_bias', 'sem')# ).reset_index()plt.figure(figsize=(7, 4.5))# Individual observationsplt.scatter(fitted_r2, relative_bias, s=40, color="tab:gray", alpha=0.5, label="Individual observations")# LOWESS curvelo = lowess(relative_bias, fitted_r2, frac=0.8, it=0, return_sorted=True)plt.plot(lo[:,0], lo[:,1], color="tab:red", lw=2, label="LOWESS", zorder=5, marker="+")# Mean relative bias at each level with error bars (95% CI)# plt.errorbar(level_stats['mean_fitted'], level_stats['mean_rel_bias'], # yerr=1.96 * level_stats['se_rel_bias'],# fmt='x', color='tab:orange', markersize=5, capsize=5, # capthick=2, linewidth=2, label='Level means ± 95% CI', zorder=4)plt.axhline(0, color="black", lw=1, ls="--")plt.xlabel("Fitted values")plt.ylabel("Relative bias (%)")plt.title("Relative Bias vs Fitted (LOWESS)")plt.legend(loc='best')plt.tight_layout()plt.show()
Figure 2: Relative bias vs fitted values with LOWESS smoother
The LOWESS curve shows systematic deviation with relative bias reaching up to +5% at low concentrations (x=0.1). This confirms lack of fit. High leverage points at \(x = 10\) pull the slope, creating proportionally larger bias at lower concentrations.
Leverage and influence concepts
What is leverage?
Leverage quantifies an observation’s potential to influence regression estimates based solely on its position in the predictor space (x-values). It measures distance from the center of the data. In simple regression, leverage increases with distance from \(\bar{x}\). Extreme x-values have high leverage. Leverage is about potential influence and depends only on \(x\), not on how well the point fits (\(y\)).
What is Cook’s distance?
Cook’s distance measures actual influence that is how much the fitted model changes when an observation is removed. It combines leverage with residual size. High leverage + large residual = high influence. High leverage + small residual = low influence (point fits the model well despite extreme position).
When to use these diagnostics
Use leverage to:
Identify observations with potential to dominate regression estimates
Check if design is balanced (extreme x-values can be problematic)
Use Cook’s distance to:
Identify influential outliers that substantially alter fitted coefficients
Assess sensitivity of results to individual observations
These diagnostics identify individual influential points (but not systematic group biases as for our biased dataset). A group of observations with similar x-values can collectively bias the model without any single point having high Cook’s distance which is why ANOVA lack-of-fit testing remains essential.
Tip
In Ordinary Least Squares (OLS) regression, the method minimizes the sum of the squared residuals, not absolute errors. This means that larger absolute errors have a disproportionately greater influence on the model fit than smaller ones, even if their relative percentage error is the same. For instance, a 10% error at a high value (e.g., x=10) contributes far more to the total squared error than a 10% error at a low value (e.g., x=0.1), because the squared error for the former is much larger in magnitude. Thus, OLS inherently gives more weight to errors associated with higher values, which can bias the model toward fitting large observations more closely
Use weighted least square regression when your data shows unequal variance common in analytical methods where precision depends on concentration. It ensures that less precise observations contribute less to the regression, improving accuracy.
Leverage and influence diagnostics for our example
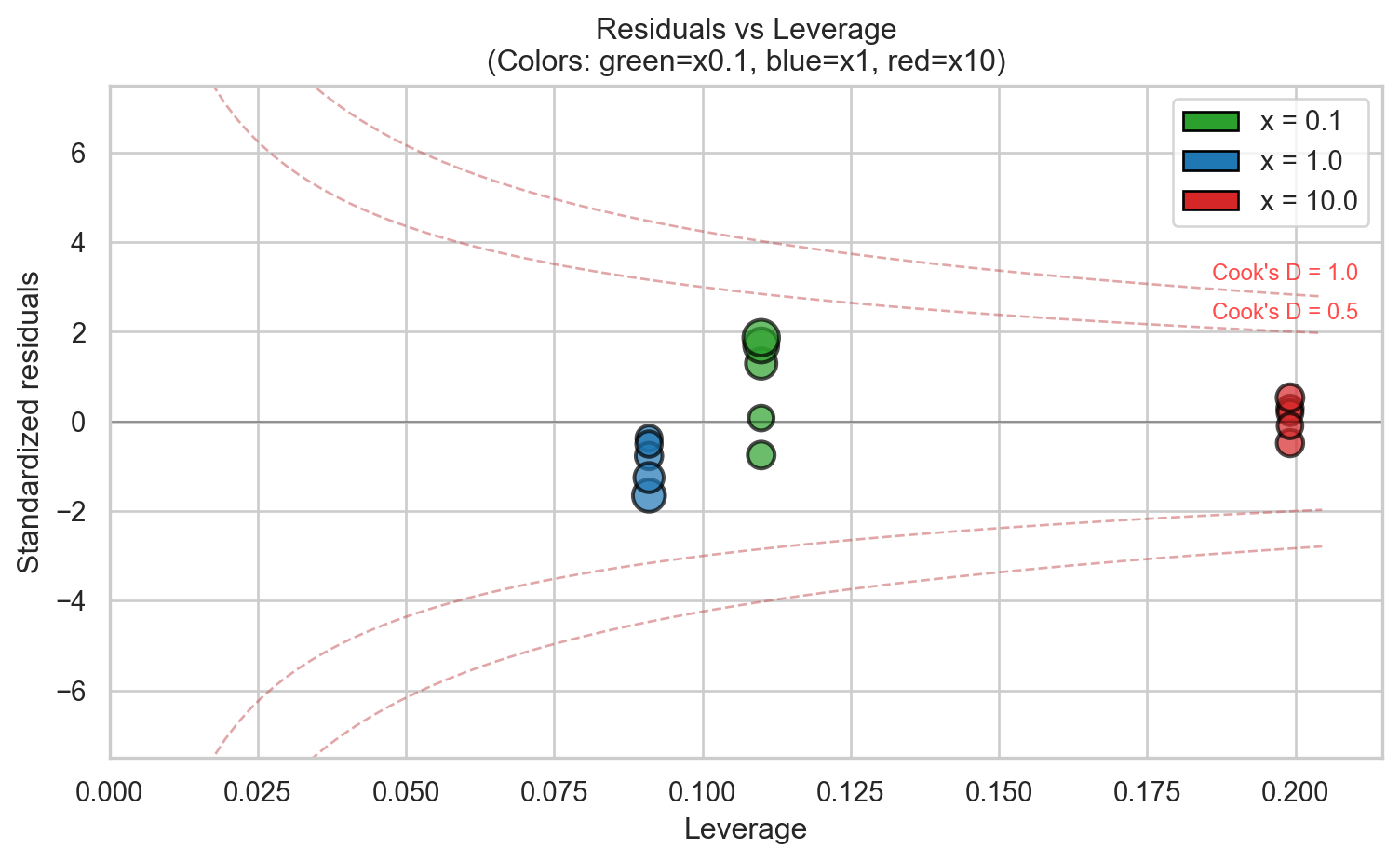
Residuals vs Leverage plot
The classic diagnostic plot (Figure 3) identifies influential cases by showing which observations combine high leverage with large residuals:
No observations exceed the conventional threshold (4/n = 0.267). The highest Cook’s distances are at x=0.1 (obs 3: 0.216, obs 2: 0.178), not at x=10. This illustrates an important point:
Points at x=0.1 and x=10 both have high leverage (far from mean x)
Points at x=0.1 have moderate residuals → moderate Cook’s D
Points at x=10 have large residuals BUT they’re consistent (all systematically biased together) → their individual influence is diluted
The systematic bias at x=10 affects the slope but doesn’t make individual points stand out as outliers
This shows that influence diagnostics alone don’t catch systematic lack-of-fit which is why ANOVA testing is essential.
Summary and recommendations
Pharmacist’s Checklist:
Plot visual diagnostics: Scatter plots with LOWESS, residuals vs fitted values
Perform formal testing: ANOVA lack-of-fit test (linear vs saturated model)
Search for influence: Cook’s distance, leverage analysis
Key takeaways:
R² alone is insufficient as it measures variance explained, not functional form
Standard diagnostics (Omnibus, Jarque-Bera) test assumptions / inference, not linearity
ANOVA lack-of-fit is the gold standard for detecting systematic deviations
Leverage ≠ Influence: High leverage only matters when combined with poor fit
Always plot residuals to visualize patterns that statistics might miss
Footnotes
Without replication, residuals combine together random noise and misspecification, so lack of fit must be inferred indirectly (e.g., by adding curvature terms or comparing to flexible models).↩︎
Pure error is the variability observed among replicate responses at the same \(X\). It captures measurement noise and other within‑level randomness and is used to estimate the “pure” residual variance. It may be associated with random errors↩︎
Lack of fit is the portion of residual variability due to model misspecification (for example, curvature when fitting a linear model). It reflects systematic differences between the fitted model and the true level means also called systemic bias.↩︎
Locally weighted scatterplot smoothing is a statistical method that smooths scattered data points to reveal the underlying trend by fitting many small, simple curves rather than one straight line↩︎